Google Cloud Platform(GCP) Creating a Project and a Compute Engine Instance with a Startup Script Attached and Auto-scaling Process

Plan of the post:
1. Creating GCP project
2. Enabling the Compute Engine Service API
3. Creating Instance
4. Starting Instance with Startup Script
— 4.a — Creating Bucket
— 4.b — Creating a Startup Script
— 4.c — Outcome of Startup Script
— 4.d — Last Touch: Providing the Startup Script via Cloud Storage
5. Auto Scaling Compute Engine Instance
— 5.a — Creating Instance Template and an Instance from Template
— 5.b — Creating Managed Instance Groups (MIG) and Setting Up Auto-Scaling
Creating a Project
There are three ways of creating a project in GCP the first one from GCP web UI , the second one from Terminal and the third one is via API. We will examine web UI and terminal.

Web UI: After entering GCP select project drop-down left upper side

and a new popup will appears which contains a list of all projects. Also, you can create a new project by clicking the ‘new project’ button right upper side.

We will name our project as the ‘Compute Engine Test’. It will take several seconds to create a new project.
Now we have a new project.
Terminal: Creating a project from Terminal is very straight forward. We open the embedded terminal at GCP.

$gcloud projects create compute-engine-terminal
End result:

Enable Compute Engine Service API
Before, enabling the Compute Engine Service API, I will be deliberately fired Error for you to see differences.
API [compute.googleapis.com] not enabled on project [169072720064].
Would you like to enable and retry (this will take a few minutes)?(y/N)? n
ERROR: (gcloud.compute.instances.list) HTTPError 403: Access Not Configured.

If we look to the services list there is no Compute Engine listed in.
Also, you can check it from ‘APIs & Services’ tab too.
Also, I want to show you ‘IAM & Admin’ permissions too. There is just my email there. We will check it after activating the Compute Engine API.

But when we try to enable API, we face another error ‘Billing must be enabled for activation of service’. Every project has to link a billing account. I already created a billing account and linked that account with another project. But you can check this link for billing account creation. Remember that when you design architecture, try to make your component as loosely coupled as possible this is why I created a separate project for the Billing account


I clicked ‘ENABLE BILLING’ and set an Account. It takes several seconds.

and now API enabled. If I look IAM & Admin tab there will be 3 other members as an addition to the previous one.

also when we list, Compute Engine API will be there.

Creating Instance
As always there are three ways to create a compute engine instance from terminal, web UI and via API. I will continue with Web UI after this point of post but you can try doing the same things by terminal or API. For example, you can create one from the terminal even though it needs a little bit configuration.
We are choosing the Compute Engine tab from the left bar. We will see the create button after clicking it, there will be a list for configuration.

Now I want to create an instance that qualifies for the free tier. So I will pick a region and zone that are in the United States but not in Northern Virginia also F1 micro as machine type. You will notice console providing us some valuable information as we play configuration like how much cost our selection to us.
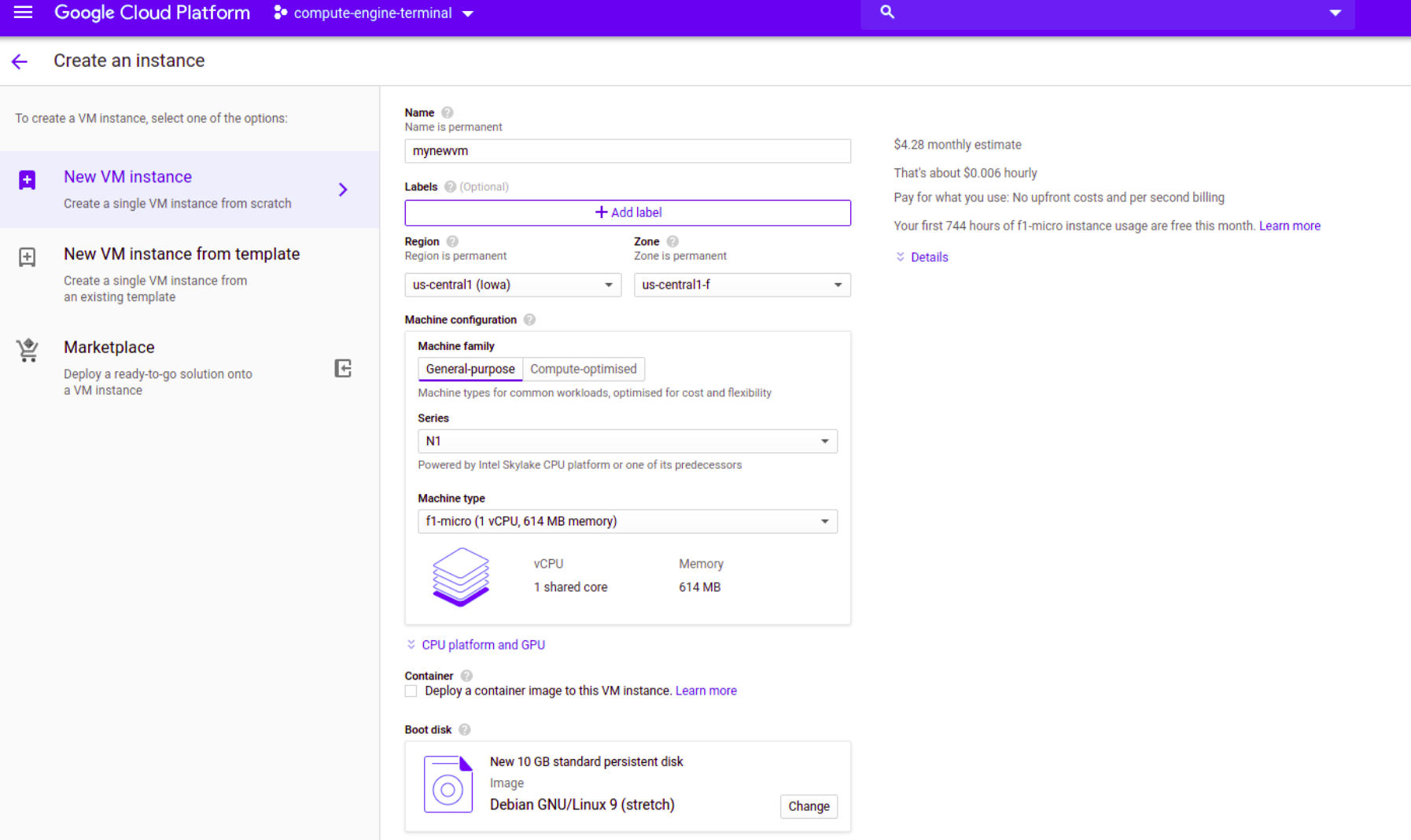
Also, there are lots of other configurations we can tweak but for now, that is enough and we leave the rest of it as is and hit the create button at the end of the page. But if you want to learn more you can visit Google documentation and I also recommend you check some configurations which are the Startup script, Metadata, Preemptibility and Automatic start. Creating a new Compute Engine instance will take a couple of seconds.
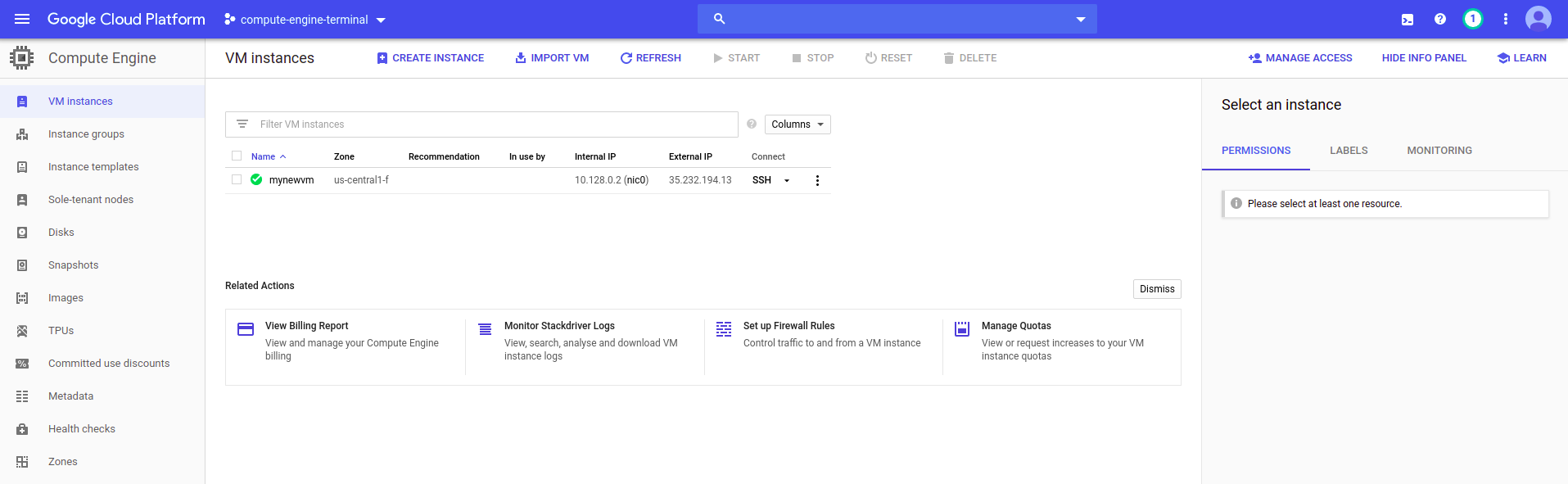
Starting Instance with Startup Script
We have a Compute Engine instance but it does nothing and this is not satisfying for me. So I want to do some fancy staff and to use as much as a feature I can. I am going to create a startup script that runs when the instance starts every time also create a bucket to put my log files.
Creating Bucket
We select Storage from the side menu,



I named my bucket as compute-engine-bucket and choose the region as location type and us-west2 for free tier and clicked create.

So we created a bucket and it is time to connect it to Compute Engine. We can set a bucket whether at the creation of VM instance or after by editing already created VM. I am going to add the one that already created.
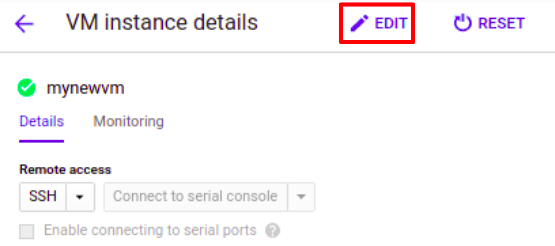
Notice how we write the bucket name gs://<bucket-name>/
Troubleshooting
After I deployed my script, I got “AccessDeniedException: 403 Insufficient Permission” error when instance tried to copy the log to the storage(bucket). It is self-explanatory but means that my VM instance doesn’t have the required permission.

So how can we give permission VM to access Storage? Answer: Service Account
A service account is a special account that can be used by services and applications running on your Compute Engine instance to interact with other Google Cloud APIs. Apps can use service account credentials to authorize themselves to a set of APIs and perform actions within the permissions granted to the service account and virtual machine instance. In addition, you can create firewall rules that allow or deny traffic to and from instances based on the service account that you associate with each instance.
I copied VM instance service account which can be found VM instance detail and added it to the storage bucket.


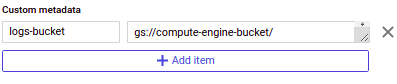
But what if we don’t want to add my service account every time we create an instance. When we are creating a bucket there is an option called “Choose how to access to object” and there is an explanation for each option. The step accepts “Fine-grained” as default therefor we have to need to add every time we create an instance but if we change it as “uniform” we no longer need to add every service account at the permission list of the bucket.
Creating a Startup Script
You can find detailed usage of the startup script at this link. Also, I am going to add all the sources that I use to create this startup script.
So what do we plan to do?
1- Making available system logs in Stackdriver Logs
2- Putting under stress our VM instance to monitor performance
3- Copying log files into the bucket
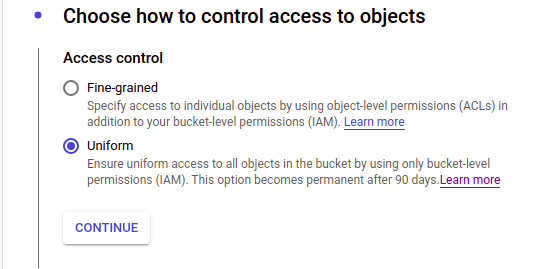
#! /bin/bash#
# -x : the xtrace option can be applied to a script by invoking Bash with the -x switch. This tells Bash to show us what each statement looks like after evaluation, just before it is executed.
# -v : oposite of -x, shows each line before it is evaluated instead of after. Options can be combined and by using both -xv
# GCE startup script output shows up in "/var/log/syslog".
#
set -x#
# noninteractive : This is the anti-frontend. It never interacts with you at all, and makes the default answers be used for all questions.
#
export DEBIAN_FRONTEND=noninteractive#
# up to date system
# -y : Automatic yes to prompts; assume "yes" as answer to all prompts and run non-interactively
# -q : Quiet. Produces output suitable for logging, omitting progress indicators.
#
apt-get -yq update
apt-get -yq upgrade#
# Install Google's Stackdriver logging agent
# https://cloud.google.com/logging/docs/agent/installation
#
curl -sSO https://dl.google.com/cloudagents/install-logging-agent.sh
bash install-logging-agent.sh#
# Install "stress" tool
# Run the stress command to spawn 8 workers spinning on sqrt() with a timeout of 120 seconds
#
apt-get -yq install stress
stress -cpu 8 -timeout 120#
# Report that we're done.
## Metadata should be set in the "logs-bucket" attribute using the "gs://mybucketname/" format.
log_bucket_metadata_name=logs-bucket
log_bucket_metadata_url="http://metadata.google.internal/computeMetadata/v1/instance/attributes/${log_bucket_metadata_name}"
worker_log_bucket=$(curl -H "Metadata-Flavor: Google" "${log_bucket_metadata_url}")# We write a file named after this machine.
worker_log_file="machine-$(hostname)-finished.txt"
echo "Eureka :) Work completed at $(date)" >"${worker_log_file}"# And we copy that file to the bucket specified in the metadata.
echo "Copying the log file to the bucket..."
gsutil cp "${worker_log_file}" "${worker_log_bucket}"
I am going to add the startup script directly and as a next step, we are going to carry it to storage.
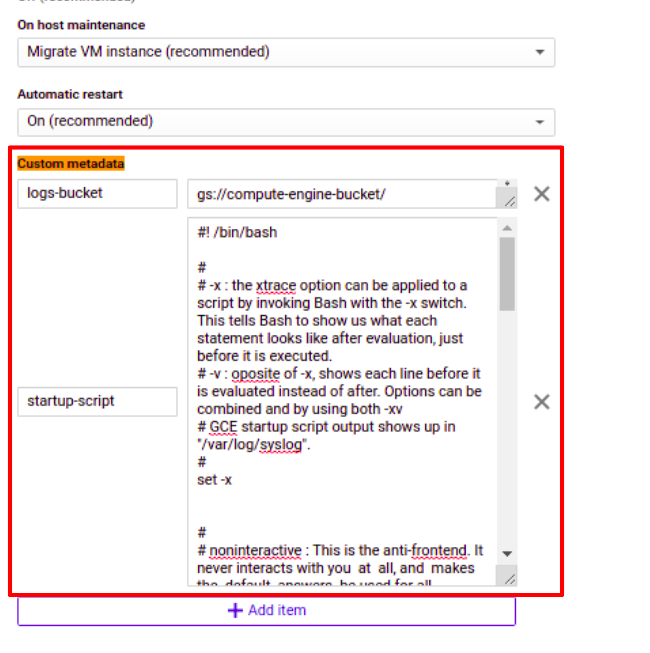
We have one more thing when I created my VM I left Cloud API access scopes as “Allow default access” but the problem is default access has only read access and not write access to “Storage” so I am going to change it. We have to stop VM to change Cloud API access scopes.
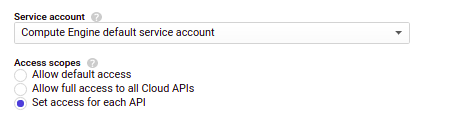

Now, I am going to start my VM and watch what will happen :)

Outcome of Startup Script
1- Making available system logs in Stackdriver Logs
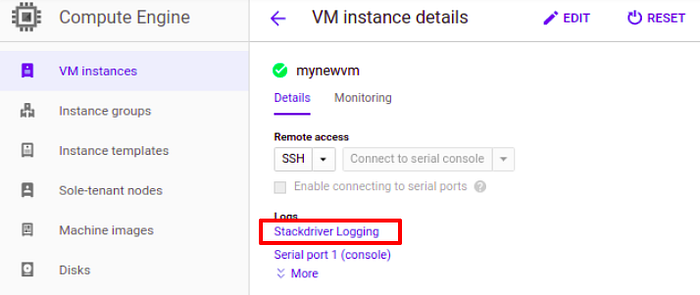
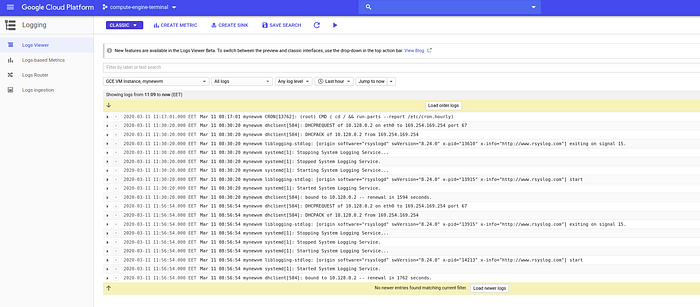
2- Putting under stress our VM instance to monitor performance

3- Copying log files into the bucket




Last Touch: Providing the Startup Script via Cloud Storage
We have to make a couple of changes to get and run the startup script. First, we have to update Cloud API access scope of VM instance and give Read/Write permission to the Storage
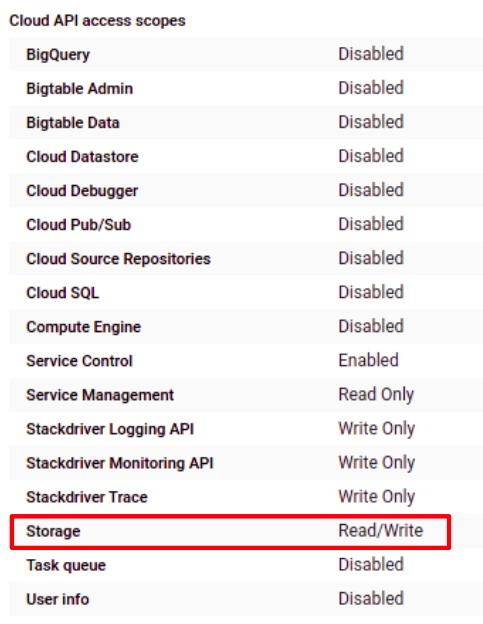
Before upload, your startup script makes sure it is formatted “Unix(LF)” format or you can get an error. I used “dos2unix startup-script.sh” command to make sure my formatting correct. You can download “doas2unix” via “sudo apt install dos2unix” command
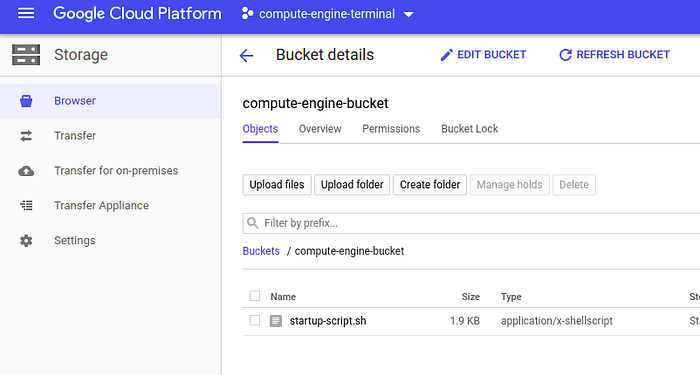
After we upload our startup script to Storage bucket, copy its URI, we can also use Link URL too but I am going to use URI. There are also differences between them but they are not the topic of this post.

Now we update metadata of VM instance according to picture to get the startup script from storage.

And everything works fine :) we can see it at the Stackdriverlogs


I also recommend “Manage Google Compute Engine with Node.js” post that belongs to Franziska Hinkelmann who shows how can you create a Compute Engine instance with a startup script via Node.js
Auto Scaling Compute Engine Instance
Managed instance groups offer autoscaling capabilities that let you automatically add or delete instances from a managed instance group based on increases or decreases in load. Autoscaling helps your apps gracefully handle increases in traffic and reduce costs when the need for resources is lower. You define the autoscaling policy and the autoscaler performs automatic scaling based on the measured load.
Autoscaling works by adding more instances to your instance group when there is more load (upscaling), and deleting instances when the need for instances is lowered (downscaling).
Creating Instance Template and an Instance from Template
An instance template is a resource that you can use to create Virtual Machine (VM) instances and managed instance groups (MIGs).
Instance templates define the machine type, boot disk image or container image, labels, and other instance properties.
Use instance templates any time you want to quickly create VM instances based off of a preexisting configuration.
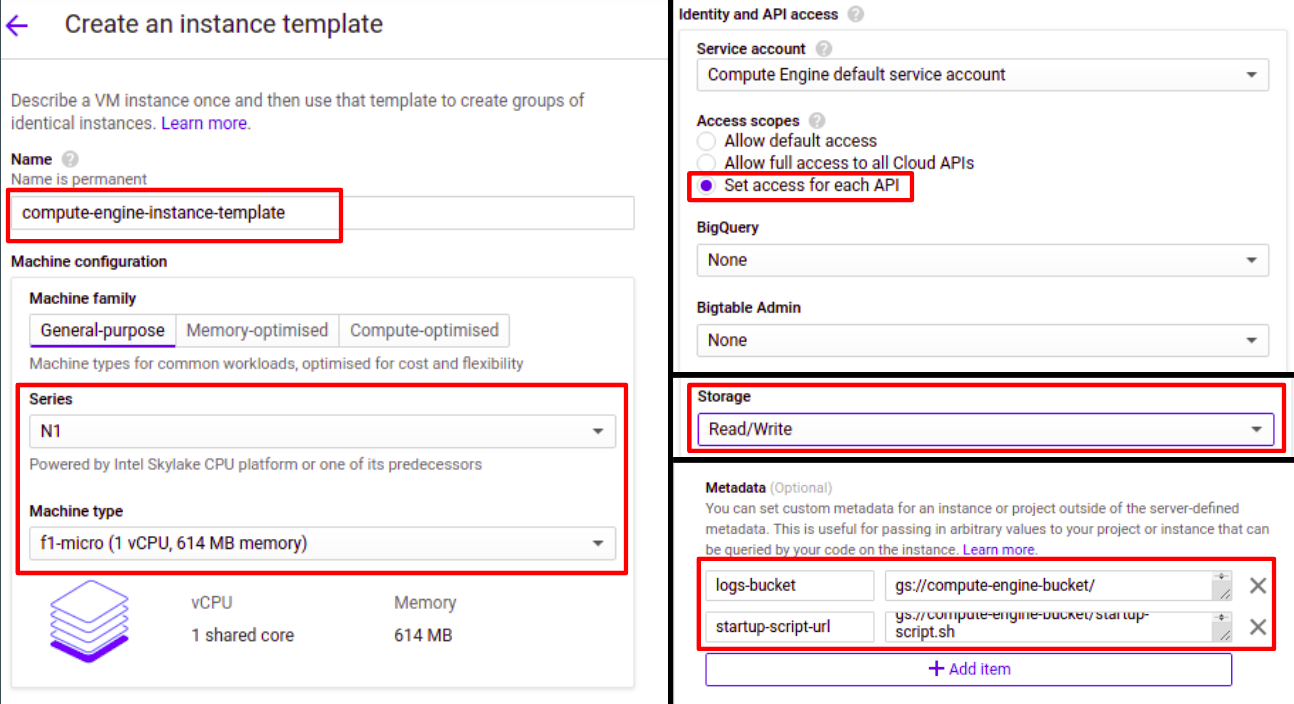
We created our instance template.

If we click it, we can see the detail of it and also some options that we can do with that template.

Next, we are going to create an instance from this template.

I leave everything as it is but instance name which I choose one that I see more suitable and hit create button. GCP created an instance and it worked as we expected at least mine worked as I expected.

Creating Managed Instance Groups (MIG) and Setting Up Auto-Scaling
A managed instance group (MIG) contains identical virtual machine (VM) instances that are based on an instance template. MIGs maintain high availability of your applications by proactively keeping your VMs available, that is, in the
RUNNINGstate.MIGs support autohealing, load balancing, autoscaling, and auto-updating.


These are my configuration of MIG and you are free to play with them. Also, I recommend you to read documentation to get further information about them.
The important things about these configurations are as follows. First, MIG wants you to choose an instance template, not to include already created instances. This is important for auto-scaling and as you notice auto-scaling comes next. There are multiple choose for auto-scaling and we choose the “ auto-scale option “ because we want from google to create and delete our instance the parameters that we gave. Therefore, Autoscaling metrics follow and I choose “CPU utilization: 30%” because as you remember we put our instances in CPU stress in the startup script to monitor. I choose 30seconds as a cool-down period you can read what it is in here also I want always at least one instance to be available, most importantly at least 1 instance has to be run if you are working with Compute Engine and I want them to scale max 4 instances. Auto healing is another important thing and again I recommend you to read the documentation for more information.
After clicking create button it directly creates a new instance and starts to scale when stress increase

If you click “Instance groups”, you will see our group is there.

For now, One instance is working because when I was writing the post, I forgot to take a screenshot of the scaling process but I can show you to scale history.

and as you see when stress increases GCP scale our instance count until it reaches 4 then when stress is started to decrease our instance count decreases with it too. Also, we can verify they are worked as we expected by looking whether they copied a log file to Storage bucket as they should do.

